How to Implement Circuit Breaker Pattern
How to Implement Circuit Breaker Pattern
When a downstream service starts failing, naive retry logic turns a partial outage into a cascading failure that takes down your entire system. The circuit breaker pattern prevents this by failing fast once a threshold is crossed, giving the struggling service time to recover while protecting upstream callers from wasting resources on requests destined to fail.
This guide demonstrates how to implement circuit breakers that actually prevent cascading failures in production systems. You'll learn the state machine mechanics, threshold tuning strategies, and the specific failure scenarios where circuit breakers either save your system or create new problems. We cover implementations in Node.js, Python, and Java with real monitoring integration and testing approaches.
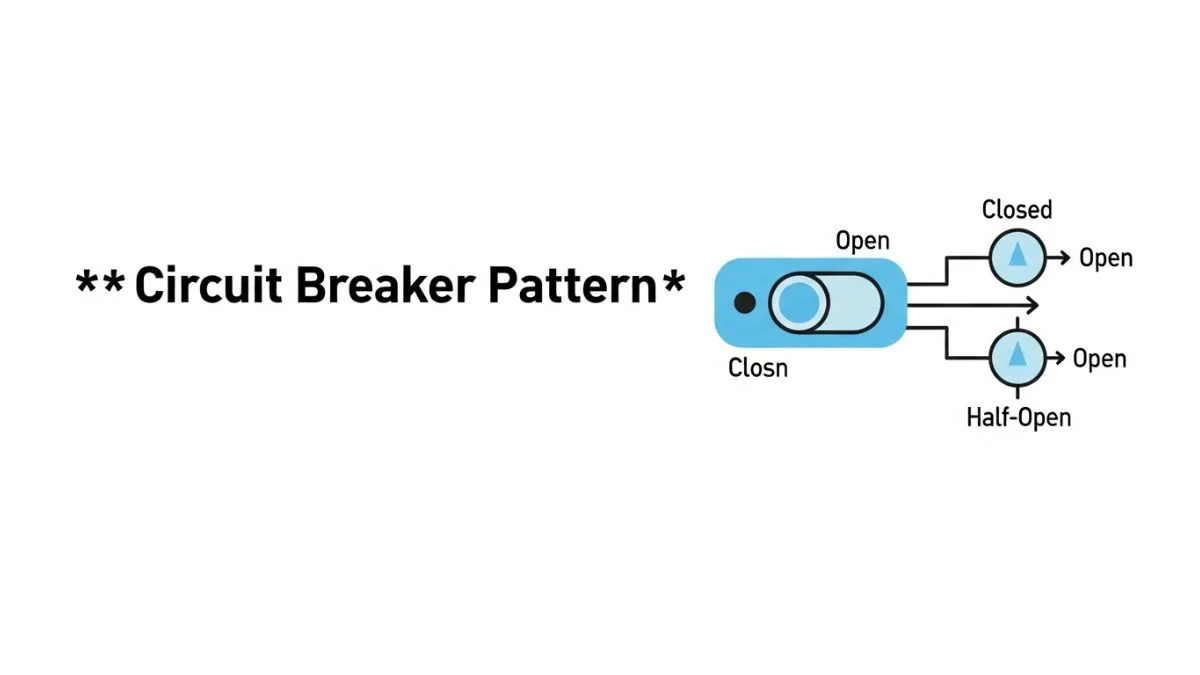
We'll walk through the three states (closed, open, half-open), when to transition between them, and the critical difference between failure rate and failure count thresholds that determines whether your circuit breaker protects your system or trips unnecessarily during traffic spikes.
What Is the Circuit Breaker Pattern
The circuit breaker pattern is a fault tolerance mechanism that monitors calls to external services and prevents cascading failures by failing fast when error rates exceed a threshold. When the "circuit" is closed, requests flow normally. When failures cross the threshold, the circuit "opens" and immediately rejects requests without attempting the call. After a timeout period, the circuit enters a "half-open" state that allows a limited number of test requests to determine if the downstream service has recovered.
The pattern solves a specific architectural problem: when a downstream service becomes slow or unavailable, upstream services continue hammering it with requests, consuming threads, connections, and memory while waiting for timeouts. This resource exhaustion propagates upstream, creating a cascading failure where one struggling service takes down everything that depends on it.
Circuit breakers break this cascade by detecting the degraded service quickly and failing immediately, freeing up resources that would otherwise be wasted waiting for timeouts. The key insight is that once you know a service is down, continuing to call it wastes resources without providing value.
When Circuit Breakers Actually Help
Circuit breakers solve cascading failure problems but create operational complexity. Understanding when they provide net value prevents adding unnecessary failure modes to your system.
Scenarios Where Circuit Breakers Are Essential
Synchronous service-to-service calls in microservices architectures benefit most from circuit breakers. When Service A calls Service B calls Service C, and C starts failing, circuit breakers in B prevent A from experiencing the same degradation. Without circuit breakers, thread pools fill up waiting for timeouts, memory pressure increases from queued requests, and the failure propagates.
External API dependencies with unreliable SLAs require circuit breakers. When you call a third-party payment processor, email service, or geocoding API, you can't control their availability. Circuit breakers ensure their outages don't cause resource exhaustion in your system.
Database connection pools benefit from circuit breakers when the database becomes overloaded. If your database starts timing out queries due to resource contention, circuit breakers prevent the application from exhausting its connection pool waiting for responses that won't come.
Scenarios Where Circuit Breakers Add Unnecessary Complexity
Asynchronous message queue consumers don't benefit from circuit breakers because the queue itself provides natural backpressure. If a consumer can't process messages, they remain in the queue rather than causing resource exhaustion. Adding circuit breakers creates a scenario where messages are rejected even though the queue can buffer them.
Read-through caching patterns with fallbacks don't need circuit breakers on the fallback path. If your cache read fails and you fall back to the database, a circuit breaker on the database call can leave you with neither cached nor fresh data.
Client-to-server calls in single-page applications rarely benefit from circuit breakers. If your API server is down, the client's circuit breaker state is useless because users can't do anything anyway. Better to let the browser's retry logic handle transient failures and show users a proper error for sustained outages.
State Machine Mechanics
Circuit breaker behavior is defined by a three-state machine. Understanding the transition logic and state-specific behaviors is critical for tuning circuit breakers that protect your system without tripping unnecessarily.
Closed State: Normal Operation
In the closed state, all requests pass through to the downstream service. The circuit breaker tracks success and failure metrics within a sliding time window. When the failure rate or failure count exceeds the configured threshold, the circuit transitions to the open state.
The closed state should track both failures and total requests. Using only a failure count creates false trips during traffic spikes because 10 failures out of 10,000 requests is healthy, but 10 failures out of 15 requests indicates a problem. Failure rate thresholds (percentage-based) handle traffic variations better than absolute failure counts.
The sliding window approach matters significantly. A fixed window that resets every 60 seconds can miss problems that occur just before the reset. A sliding window that continuously tracks the last 60 seconds of requests detects failures regardless of when they start.
Open State: Failing Fast
In the open state, the circuit breaker immediately rejects all requests without attempting the call. This prevents resource exhaustion and gives the downstream service time to recover. The circuit breaker returns a fallback response, throws an exception, or returns an error depending on your implementation.
The open state must include a timeout. After this timeout expires, the circuit transitions to half-open state to test if the downstream service has recovered. Typical timeout values range from 5 to 60 seconds depending on how quickly you expect services to recover and how much traffic you can afford to reject.
A common mistake is making the timeout too short. If the downstream service needs 30 seconds to recover but your timeout is 5 seconds, the circuit breaker will repeatedly test the service while it's still struggling, potentially preventing its recovery.
Half-Open State: Testing Recovery
In the half-open state, the circuit breaker allows a limited number of test requests through to the downstream service. If these requests succeed, the circuit closes and normal operation resumes. If they fail, the circuit reopens and the timeout restarts.
The number of test requests is a critical tuning parameter. Too few test requests and transient failures will unnecessarily reopen the circuit. Too many test requests and you risk overwhelming a service that's still recovering.
Most implementations allow exactly one concurrent request in half-open state, with subsequent requests failing fast until that test request completes. This prevents thundering herd problems where a dozen threads all test the service simultaneously the moment the timeout expires.
Implementation in Node.js
Node.js circuit breaker implementations must handle the event loop's asynchronous nature. The Opossum library provides a production-ready circuit breaker with proper state management and monitoring hooks.
const CircuitBreaker = require('opossum');
// Function that calls the downstream service
async function callExternalAPI(userId) {
const response = await fetch(`https://api.example.com/users/${userId}`);
if (!response.ok) {
throw new Error(`API returned ${response.status}`);
}
return response.json();
}
// Circuit breaker configuration
const options = {
timeout: 3000, // Request timeout in ms
errorThresholdPercentage: 50, // Open circuit at 50% failure rate
resetTimeout: 30000, // Try half-open after 30 seconds
rollingCountTimeout: 10000, // 10 second rolling window
rollingCountBuckets: 10, // Divide window into 10 buckets
volumeThreshold: 10 // Minimum requests before checking threshold
};
const breaker = new CircuitBreaker(callExternalAPI, options);
// Fallback function when circuit is open
breaker.fallback((userId) => {
return { id: userId, name: 'Unknown', cached: true };
});
// Event handlers for monitoring
breaker.on('open', () => {
console.error('Circuit breaker opened');
metrics.increment('circuit_breaker.open');
});
breaker.on('halfOpen', () => {
console.log('Circuit breaker half-open, testing');
metrics.increment('circuit_breaker.half_open');
});
breaker.on('close', () => {
console.log('Circuit breaker closed');
metrics.increment('circuit_breaker.close');
});
// Usage in your application
async function getUserData(userId) {
try {
return await breaker.fire(userId);
} catch (error) {
// Handle circuit breaker rejection
if (error.message.includes('breaker is open')) {
return { error: 'Service temporarily unavailable' };
}
throw error;
}
}The volumeThreshold parameter prevents the circuit from opening due to a few failures during low traffic periods. With volumeThreshold set to 10, the circuit breaker needs at least 10 requests in the rolling window before it can open, preventing false trips when the service is barely being used.
The rollingCountBuckets parameter divides the rolling window into time slices. With a 10-second window and 10 buckets, each bucket represents 1 second of data. This sliding window approach provides more accurate failure rate calculations than a fixed window.
Implementation in Python
Python circuit breaker implementations must handle both synchronous and asynchronous contexts. The PyBreaker library provides a decorator-based approach that works with regular functions and async functions.
from pybreaker import CircuitBreaker, CircuitBreakerError
import requests
from typing import Dict, Any
# Configure circuit breaker
breaker = CircuitBreaker(
fail_max=5, # Open after 5 consecutive failures
timeout_duration=30, # Try half-open after 30 seconds
reset_timeout=60, # Close if successful for 60 seconds in half-open
expected_exception=requests.RequestException
)
@breaker
def call_user_service(user_id: str) -> Dict[str, Any]:
"""Call external user service with circuit breaker protection."""
response = requests.get(
f'https://api.example.com/users/{user_id}',
timeout=3
)
response.raise_for_status()
return response.json()
def get_user_data(user_id: str) -> Dict[str, Any]:
"""Get user data with fallback handling."""
try:
return call_user_service(user_id)
except CircuitBreakerError:
# Circuit is open, return fallback
return {
'id': user_id,
'name': 'Unknown',
'error': 'Service temporarily unavailable'
}
except requests.RequestException as e:
# Request failed but circuit didn't open yet
return {'error': str(e)}
# For more complex configurations with failure rate
class AdvancedCircuitBreaker(CircuitBreaker):
def __init__(self, failure_threshold_percent: float = 50.0,
window_size: int = 10, **kwargs):
super().__init__(**kwargs)
self.failure_threshold = failure_threshold_percent
self.window_size = window_size
self.recent_calls = []
def call(self, func, *args, **kwargs):
"""Override call method to track failure rate."""
if self._state.name == 'open':
raise CircuitBreakerError(self)
try:
result = func(*args, **kwargs)
self._record_success()
return result
except Exception as e:
self._record_failure()
if self._should_open():
self.open()
raise
def _record_success(self):
self.recent_calls.append(True)
self._trim_window()
def _record_failure(self):
self.recent_calls.append(False)
self._trim_window()
def _trim_window(self):
if len(self.recent_calls) > self.window_size:
self.recent_calls = self.recent_calls[-self.window_size:]
def _should_open(self) -> bool:
if len(self.recent_calls) < self.window_size:
return False
failure_count = sum(1 for x in self.recent_calls if not x)
failure_rate = (failure_count / len(self.recent_calls)) * 100
return failure_rate >= self.failure_thresholdPyBreaker's fail_max parameter uses consecutive failures rather than failure rate, which can cause issues during traffic spikes. The custom implementation above tracks failure rate over a sliding window, providing more nuanced behavior that matches production traffic patterns.
The expected_exception parameter tells the circuit breaker which exceptions should count as failures. Setting this to requests.RequestException ensures that only actual request failures trip the circuit, not application-level errors like validation failures or business logic exceptions.
Implementation in Java with Resilience4j
Java's Resilience4j library provides the most sophisticated circuit breaker implementation with extensive configuration options and integration with Spring Boot.
import io.github.resilience4j.circuitbreaker.CircuitBreaker;
import io.github.resilience4j.circuitbreaker.CircuitBreakerConfig;
import io.github.resilience4j.circuitbreaker.CircuitBreakerRegistry;
import java.time.Duration;
import java.util.function.Supplier;
public class UserServiceClient {
private final CircuitBreaker circuitBreaker;
public UserServiceClient() {
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // Open at 50% failure rate
.slowCallRateThreshold(50) // Consider slow calls as failures
.slowCallDurationThreshold(Duration.ofSeconds(2))
.waitDurationInOpenState(Duration.ofSeconds(30))
.permittedNumberOfCallsInHalfOpenState(3)
.minimumNumberOfCalls(10)
.slidingWindowType(CircuitBreakerConfig.SlidingWindowType.TIME_BASED)
.slidingWindowSize(10) // 10 second window
.recordExceptions(IOException.class, TimeoutException.class)
.ignoreExceptions(BusinessException.class)
.build();
CircuitBreakerRegistry registry = CircuitBreakerRegistry.of(config);
this.circuitBreaker = registry.circuitBreaker("userService");
// Register event listeners
circuitBreaker.getEventPublisher()
.onStateTransition(event -> {
System.out.println("Circuit breaker state: " +
event.getStateTransition());
metrics.recordStateChange(event.getStateTransition());
})
.onError(event -> {
System.err.println("Circuit breaker error: " +
event.getThrowable().getMessage());
});
}
public User getUser(String userId) {
Supplier decoratedSupplier = CircuitBreaker
.decorateSupplier(circuitBreaker, () -> callUserAPI(userId));
try {
return decoratedSupplier.get();
} catch (CallNotPermittedException e) {
// Circuit is open
return getFallbackUser(userId);
}
}
private User callUserAPI(String userId) throws IOException {
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://api.example.com/users/" + userId))
.timeout(Duration.ofSeconds(3))
.build();
HttpResponse response = client.send(request,
HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
throw new IOException("API returned " + response.statusCode());
}
return parseUser(response.body());
}
private User getFallbackUser(String userId) {
return new User(userId, "Unknown", true);
}
} Resilience4j's slowCallDurationThreshold treats slow responses as failures, preventing the circuit from staying closed while the downstream service degrades slowly rather than failing outright. This is critical for services that respond with 200 status codes but take 30 seconds to do so.
The permittedNumberOfCallsInHalfOpenState parameter controls how many test requests are allowed in half-open state. Setting this to 3 means three successful requests must complete before the circuit closes, providing more confidence that the service has recovered than a single successful request would.
The ignoreExceptions parameter prevents application-level exceptions from tripping the circuit. If your service throws a ValidationException because the user submitted invalid data, that shouldn't count as a service failure that trips the circuit breaker.
Threshold Tuning Strategies
Circuit breaker effectiveness depends entirely on proper threshold configuration. Too sensitive and circuits trip during normal traffic variance. Too lenient and cascading failures spread before circuits open.
Failure Rate vs Failure Count
Failure rate thresholds (percentage-based) adapt to traffic volume changes. A 50% failure rate threshold trips the circuit when half of requests fail, whether that's 5 out of 10 requests or 500 out of 1,000. This prevents false trips during low traffic and ensures protection during high traffic.
Failure count thresholds (absolute number) work well for services with consistent traffic patterns. Opening the circuit after 10 consecutive failures provides predictable behavior when request rates stay steady, but causes problems when traffic varies significantly.
The minimum request threshold prevents circuits from tripping based on insufficient data. With a 50% failure rate and minimum of 10 requests, the circuit won't open if you've only seen 3 failures out of 5 requests. This prevents false trips during service startup or low traffic periods.
Timing Configuration
The request timeout must be shorter than the circuit breaker's measurement window. If your timeout is 5 seconds and your sliding window is 10 seconds, you'll only capture 2 timed-out requests before measuring failure rates, which may not be enough data for accurate decisions.
The open state timeout should align with your service's recovery time. If your service takes 60 seconds to recover from memory pressure, a 10-second timeout means the circuit breaker will test the service six times during its recovery period, potentially preventing that recovery.
The half-open state's test request count balances fast recovery against premature closure. One test request closes the circuit immediately if it succeeds, which works well for transient failures but risks closing too soon for services with intermittent issues. Three to five test requests provide more confidence at the cost of slower recovery.
Production Tuning Process
Start with conservative thresholds: 50% failure rate, 20 minimum requests, 30-second open timeout. Monitor false trip rates (circuits opening during normal operation) and miss rates (cascading failures occurring before circuits open).
Adjust failure rate threshold based on false trip analysis. If circuits open during normal traffic variance, increase the threshold to 60-70%. If cascading failures spread before circuits open, decrease to 30-40%.
Tune timing based on downstream service characteristics. If the service recovers quickly from failures, reduce open timeout to 10-15 seconds. If recovery takes longer, increase to 60 seconds or implement exponential backoff where each reopening doubles the timeout.
Monitoring and Observability
Circuit breakers create operational blind spots if not properly monitored. When a circuit opens, you need to know immediately and understand why it opened.
Critical Metrics to Track
State transition events (closed to open, open to half-open, half-open to closed) indicate when circuits trip and recover. Track these as counters in your metrics system and alert when circuits open. The frequency of open events indicates either downstream service instability or overly aggressive thresholds.
Request rejection counts track how many requests failed fast because the circuit was open. High rejection counts indicate significant user impact from the downstream service failure. This metric should trigger alerts to your on-call team.
Failure rate within the sliding window shows how close the circuit is to opening. Tracking this as a gauge lets you see degradation before the circuit trips, potentially allowing proactive intervention.
Half-open state duration indicates how long it takes for the downstream service to recover. If half-open periods consistently exceed 60 seconds, your downstream service may be undersized or experiencing recurring issues that need architectural changes.
Integration with APM Tools
// Datadog integration example
const breaker = new CircuitBreaker(callService, options);
breaker.on('open', () => {
statsd.increment('circuit_breaker.state.open', {
tags: ['service:user-api', 'env:production']
});
statsd.gauge('circuit_breaker.state', 1, {
tags: ['service:user-api', 'state:open']
});
});
breaker.on('success', (result) => {
statsd.increment('circuit_breaker.success', {
tags: ['service:user-api']
});
statsd.histogram('circuit_breaker.latency', result.duration);
});
breaker.on('failure', (error) => {
statsd.increment('circuit_breaker.failure', {
tags: ['service:user-api', 'error_type:' + error.name]
});
});
breaker.on('reject', () => {
statsd.increment('circuit_breaker.reject', {
tags: ['service:user-api']
});
});Tag metrics with the downstream service name, environment, and circuit breaker instance. This enables service-specific dashboards that show circuit health across all upstream callers and helps identify whether problems are local to one caller or affecting all consumers.
Testing Circuit Breaker Behavior
Circuit breakers are notoriously difficult to test because their behavior depends on timing, state transitions, and concurrent requests. Proper testing requires simulating these conditions without creating flaky tests.
Unit Testing State Transitions
describe('Circuit Breaker State Transitions', () => {
let breaker;
let mockService;
beforeEach(() => {
mockService = jest.fn();
breaker = new CircuitBreaker(mockService, {
errorThresholdPercentage: 50,
volumeThreshold: 5,
timeout: 100,
resetTimeout: 1000
});
});
test('opens circuit after threshold failures', async () => {
// Simulate 5 failures
mockService.mockRejectedValue(new Error('Service failed'));
for (let i = 0; i < 5; i++) {
try {
await breaker.fire();
} catch (e) {}
}
expect(breaker.opened).toBe(true);
// Next request should fail fast
mockService.mockResolvedValue('success');
await expect(breaker.fire()).rejects.toThrow('breaker is open');
expect(mockService).toHaveBeenCalledTimes(5); // Didn't call on 6th request
});
test('transitions to half-open after timeout', async () => {
// Open the circuit
mockService.mockRejectedValue(new Error('Service failed'));
for (let i = 0; i < 5; i++) {
try { await breaker.fire(); } catch (e) {}
}
expect(breaker.opened).toBe(true);
// Wait for reset timeout
await new Promise(resolve => setTimeout(resolve, 1100));
expect(breaker.halfOpen).toBe(true);
// Test request succeeds
mockService.mockResolvedValue('success');
await breaker.fire();
expect(breaker.closed).toBe(true);
});
test('reopens from half-open on failure', async () => {
// Open circuit and wait for half-open
mockService.mockRejectedValue(new Error('Service failed'));
for (let i = 0; i < 5; i++) {
try { await breaker.fire(); } catch (e) {}
}
await new Promise(resolve => setTimeout(resolve, 1100));
expect(breaker.halfOpen).toBe(true);
// Test request fails
try {
await breaker.fire();
} catch (e) {}
expect(breaker.opened).toBe(true);
});
});Integration Testing with Chaos Engineering
Integration tests should verify that circuit breakers prevent cascading failures in realistic scenarios. Use tools like Toxiproxy or WireMock to simulate downstream service failures.
describe('Circuit Breaker Integration', () => {
let proxy;
beforeAll(async () => {
// Start Toxiproxy to simulate flaky downstream service
proxy = new ToxiproxyClient('localhost:8474');
await proxy.createProxy({
name: 'user-api',
listen: '127.0.0.1:8000',
upstream: 'api.example.com:443'
});
});
test('prevents resource exhaustion during downstream outage', async () => {
// Inject latency to simulate slow downstream service
await proxy.addToxic('latency', 'downstream', {
latency: 5000
});
const startTime = Date.now();
const promises = [];
// Make 100 concurrent requests
for (let i = 0; i < 100; i++) {
promises.push(
getUserData(i).catch(e => ({ error: true }))
);
}
await Promise.all(promises);
const duration = Date.now() - startTime;
// Without circuit breaker, this would take 500+ seconds (100 * 5s)
// With circuit breaker, should fail fast after threshold is hit
expect(duration).toBeLessThan(30000); // 30 seconds
const errorCount = promises.filter(p => p.error).length;
expect(errorCount).toBeGreaterThan(50); // Most requests failed fast
});
afterAll(async () => {
await proxy.deleteProxy('user-api');
});
});Fallback Strategies
When a circuit opens, your application must return something to the caller. Choosing the right fallback strategy depends on the operation type and user impact.
Cached Data Fallback
For read operations, returning stale cached data provides better user experience than an error. Implement a cache-aside pattern where successful responses are cached, and circuit breaker failures return cached values.
const cache = new Map();
breaker.fallback(async (userId) => {
const cached = cache.get(userId);
if (cached && Date.now() - cached.timestamp < 3600000) {
return { ...cached.data, fromCache: true };
}
// No valid cache, return error
throw new Error('Service unavailable and no cached data');
});
breaker.on('success', (result, userId) => {
cache.set(userId, {
data: result,
timestamp: Date.now()
});
});Include metadata indicating the response came from cache. Frontend applications can display a warning that data may be stale, and background jobs can attempt to refresh cached data once the circuit closes.
Degraded Functionality
For operations where cached data isn't available or appropriate, return a degraded response that omits non-critical data. If a user profile service fails, return basic user information from your database and omit enhanced data from the failed service.
async function getUserProfile(userId) {
let basicProfile = await db.users.findOne({ id: userId });
try {
// Try to enhance with external service data
const enhancedData = await enhancementServiceBreaker.fire(userId);
return { ...basicProfile, ...enhancedData };
} catch (error) {
// Circuit is open or service failed, return basic profile
return { ...basicProfile, enhanced: false };
}
}Default Values
For configuration services or feature flag systems, return safe default values when the circuit opens. This keeps your application running with conservative settings rather than crashing.
const DEFAULT_CONFIG = {
maxUploadSize: 10 * 1024 * 1024, // 10MB
enableBetaFeatures: false,
apiRateLimit: 100
};
breaker.fallback(() => {
logger.warn('Config service unavailable, using defaults');
return DEFAULT_CONFIG;
});Queue for Later Processing
For write operations, queue requests for processing after the circuit closes. This prevents data loss while still protecting against resource exhaustion.
const writeQueue = [];
breaker.fallback((data) => {
writeQueue.push({
data: data,
timestamp: Date.now(),
retries: 0
});
return { queued: true, queuePosition: writeQueue.length };
});
// Background job processes queue when circuit closes
setInterval(async () => {
if (breaker.closed && writeQueue.length > 0) {
const item = writeQueue.shift();
try {
await breaker.fire(item.data);
} catch (error) {
if (item.retries < 3) {
item.retries++;
writeQueue.push(item);
} else {
logger.error('Failed to process queued item after 3 retries', item);
}
}
}
}, 5000);Common Implementation Mistakes
Circuit breaker implementations fail in production due to configuration errors and misunderstanding of state transition logic. These mistakes create systems that fail to protect against cascading failures or trip unnecessarily during normal operation.
Sharing Circuit Breakers Across Different Operations
Using a single circuit breaker for all operations on a service creates problems when one operation fails while others succeed. If your DELETE endpoints start failing but GET endpoints work fine, a shared circuit breaker will block all requests even though most could succeed.
Create separate circuit breakers for each operation type or endpoint with meaningfully different failure characteristics. Group operations that fail together under one circuit breaker, but separate operations that can fail independently.
Not Handling Circuit Breaker Exceptions
When a circuit opens, breaker.fire() throws an exception. Applications that don't catch this specific exception type will crash or return 500 errors to users instead of implementing fallback behavior.
// Wrong - treats circuit breaker rejection as system error
async function getUser(id) {
return await breaker.fire(id);
}
// Right - handles circuit breaker rejection distinctly
async function getUser(id) {
try {
return await breaker.fire(id);
} catch (error) {
if (error instanceof CircuitBreakerError) {
return getCachedUser(id);
}
throw error; // Other errors bubble up
}
}Ignoring Volume Thresholds
Without minimum volume thresholds, circuit breakers trip based on the first few requests after a quiet period. Three failures out of three requests trips a circuit configured with a 50% failure rate, even though three requests isn't statistically significant.
Set volume thresholds to at least 10-20 requests. This ensures the circuit only opens when enough data exists to make a reliable failure rate calculation.
Setting Timeouts Longer Than Circuit Windows
If your request timeout is 30 seconds and your sliding window is 10 seconds, you'll measure failure rates before requests finish timing out. This delays circuit opening until after resource exhaustion has already begun.
Request timeouts should be one-third to one-half of the sliding window duration. With a 10-second window, use 3-5 second request timeouts.
Circuit Breakers in Distributed Systems
Circuit breaker behavior becomes more complex in distributed systems where multiple instances of a service each maintain independent circuit breaker state.
Independent vs Shared State
Most circuit breaker implementations maintain state locally in each application instance. When Service A has five instances calling Service B, each instance tracks its own circuit breaker state. This means one instance may have an open circuit while others continue calling Service B.
Independent state provides faster response to local failures and avoids the complexity of distributed coordination. The downside is that five instances will all test Service B independently, potentially sending 5x the test traffic during recovery.
Shared state implementations store circuit breaker state in Redis or a similar distributed cache. All instances check the shared state before making requests. This coordinates circuit behavior across instances but introduces new failure modes (what happens when Redis is down?) and adds latency to every request.
When to Use Shared State
Use shared circuit breaker state when downstream services are small and test traffic from multiple instances during recovery would overwhelm them. If Service B runs on a single small server and Service A has 50 instances, 50 instances simultaneously testing B in half-open state could cause problems.
Use independent state when downstream services are horizontally scaled and can handle test traffic from multiple callers. This is the most common case and provides better resilience because the circuit breaker doesn't depend on external state.
Bulkhead Pattern Integration
Circuit breakers prevent cascading failures but don't isolate resources between different downstream services. If Service A calls both Service B and Service C, failures in B can still exhaust A's thread pool even with circuit breakers.
The bulkhead pattern assigns separate thread pools or connection pools to each downstream service. Combine this with circuit breakers for comprehensive protection.
// Separate thread pools for different services
const userServicePool = new ThreadPool({ size: 20 });
const paymentServicePool = new ThreadPool({ size: 10 });
const userBreaker = new CircuitBreaker(
(userId) => userServicePool.execute(() => callUserService(userId)),
options
);
const paymentBreaker = new CircuitBreaker(
(paymentId) => paymentServicePool.execute(() => callPaymentService(paymentId)),
options
);
// Payment service failures can't exhaust user service threads
async function processOrder(orderId) {
const user = await userBreaker.fire(orderId.userId);
const payment = await paymentBreaker.fire(orderId.paymentId);
return { user, payment };
}Advanced Patterns
Adaptive Thresholds
Static failure rate thresholds don't adapt to changing system conditions. An adaptive circuit breaker adjusts thresholds based on recent performance history.
class AdaptiveCircuitBreaker {
constructor(baseThreshold = 50, adaptationRate = 0.1) {
this.baseThreshold = baseThreshold;
this.currentThreshold = baseThreshold;
this.adaptationRate = adaptationRate;
this.successHistory = [];
}
recordSuccess() {
this.successHistory.push(true);
this.trimHistory();
this.adaptThreshold();
}
recordFailure() {
this.successHistory.push(false);
this.trimHistory();
this.adaptThreshold();
}
trimHistory() {
if (this.successHistory.length > 100) {
this.successHistory = this.successHistory.slice(-100);
}
}
adaptThreshold() {
const recentSuccessRate = this.calculateSuccessRate();
// Lower threshold if service is performing well
if (recentSuccessRate > 95) {
this.currentThreshold = Math.max(
this.baseThreshold - 20,
this.currentThreshold - this.adaptationRate * 10
);
}
// Raise threshold if service is struggling
else if (recentSuccessRate < 85) {
this.currentThreshold = Math.min(
this.baseThreshold + 20,
this.currentThreshold + this.adaptationRate * 10
);
}
}
calculateSuccessRate() {
if (this.successHistory.length === 0) return 100;
const successes = this.successHistory.filter(x => x).length;
return (successes / this.successHistory.length) * 100;
}
}Exponential Backoff for Open State
When a circuit repeatedly opens and closes, the downstream service may need progressively longer recovery periods. Exponential backoff increases the open state timeout with each consecutive failure.
class BackoffCircuitBreaker extends CircuitBreaker {
constructor(options) {
super(options);
this.consecutiveOpens = 0;
this.baseTimeout = options.resetTimeout;
this.on('open', () => {
this.consecutiveOpens++;
const backoffTimeout = this.baseTimeout * Math.pow(2, this.consecutiveOpens - 1);
this.options.resetTimeout = Math.min(backoffTimeout, 300000); // Max 5 minutes
});
this.on('close', () => {
this.consecutiveOpens = 0;
this.options.resetTimeout = this.baseTimeout;
});
}
}Frequently Asked Questions
Should circuit breakers be used for database calls?
Circuit breakers help with database calls when the database is overloaded or network connectivity is unstable, but they complicate normal error handling. If your database goes down completely, circuit breakers help prevent connection pool exhaustion. If queries are slow due to missing indexes or large data sets, circuit breakers treat symptoms without fixing the underlying problem. Use circuit breakers for database calls in systems where database failures need to be isolated, but ensure you have proper monitoring to detect when circuits open so you can address root causes.
How do circuit breakers work with retries?
Circuit breakers should wrap retry logic, not the other way around. Execute retries first, and only count the operation as failed for circuit breaker purposes if all retries fail. If you wrap the circuit breaker with retry logic, each retry attempt will count as a separate failure, potentially tripping the circuit prematurely. Configure retries with exponential backoff and jitter before the circuit breaker sees the operation.
What happens when multiple circuit breakers trip simultaneously?
When multiple circuit breakers trip, your system enters degraded mode where many operations fail fast. This is the intended behavior because continuing to attempt failing operations would cause cascading failures. The key is having proper fallback strategies so that fast failures return meaningful responses rather than 500 errors. Monitor circuit breaker states and alert when multiple circuits open simultaneously, as this indicates a larger systemic issue.
Can circuit breakers cause split-brain scenarios?
In distributed systems where different instances maintain independent circuit breaker state, some instances may have open circuits while others have closed circuits. This isn't split-brain in the traditional sense because there's no data inconsistency, but it does mean user experience varies depending on which instance handles their request. Load balancers with session affinity can minimize this variation, or use shared circuit breaker state if consistency is critical.
How do you test circuit breakers in staging environments?
Test circuit breakers by deliberately failing downstream services using chaos engineering tools like Chaos Monkey or Toxiproxy. Create test scenarios where services return errors, respond slowly, or become completely unavailable. Verify that circuits open at the configured thresholds, requests fail fast during the open state, and circuits transition to half-open and close properly when services recover. Load testing tools should include circuit breaker behavior verification as part of their test suites.
Should every external service call use a circuit breaker?
Circuit breakers add complexity and should be used selectively. Use them for services where failures can cause resource exhaustion (synchronous calls with timeouts, connection pools, thread pools). Don't use them for asynchronous operations where natural backpressure exists, or for services where you need guaranteed delivery (use message queues with dead letter queues instead). Start with circuit breakers on your most critical and failure-prone external dependencies, then expand based on actual production incidents.
How do circuit breakers interact with rate limiters?
Circuit breakers and rate limiters solve different problems. Rate limiters prevent your service from overwhelming downstream services during normal operation. Circuit breakers prevent cascading failures when downstream services are already struggling. Use both: rate limiters as preventive measures during normal operation, and circuit breakers as protective measures during failures. The circuit breaker should wrap the rate-limited call so that rate limit rejections don't count as service failures.
What's the right balance between circuit breaker sensitivity and tolerance?
Start with a 50% failure rate threshold, 20 minimum requests, and 30-second open timeout. Monitor false trip rates (circuits opening during normal operation) and miss rates (cascading failures before circuits open). If false trips are common, increase the failure rate threshold or minimum request count. If cascading failures occur, decrease the threshold or sliding window duration. The right balance depends on your specific service SLAs and user impact tolerance. Services where availability matters more than consistency should use more aggressive thresholds.
Conclusion
Circuit breakers prevent cascading failures by detecting degraded downstream services and failing fast instead of consuming resources on doomed requests. Proper implementation requires understanding the three-state machine, configuring thresholds based on actual traffic patterns, and implementing fallback strategies that maintain user experience during outages.
The most critical decisions are choosing failure rate over failure count thresholds, setting minimum volume requirements to prevent false trips, and ensuring request timeouts are shorter than measurement windows. Monitor state transitions actively and tune thresholds based on production behavior rather than theoretical calculations.
Circuit breakers add operational complexity and should be used selectively on synchronous service-to-service calls where failures can cause resource exhaustion. Combined with proper monitoring, fallback strategies, and testing, they transform single service failures from system-wide outages into isolated degradation.